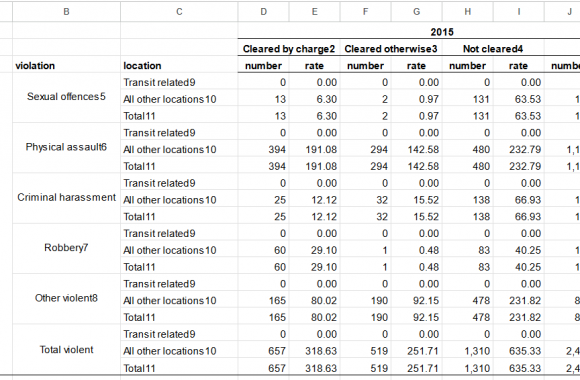
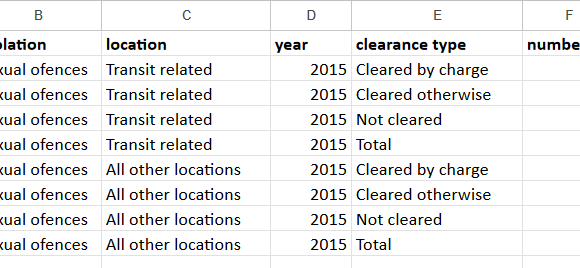
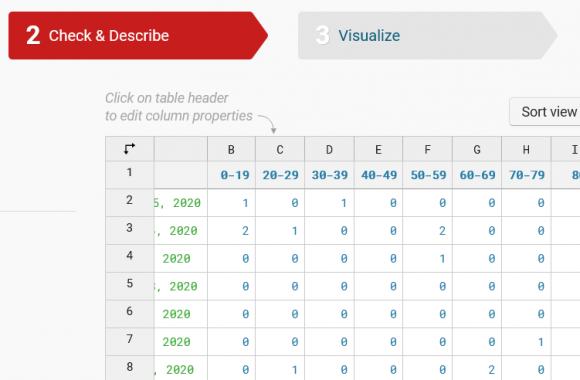
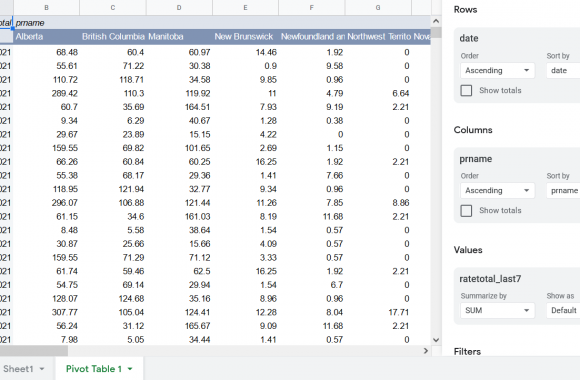
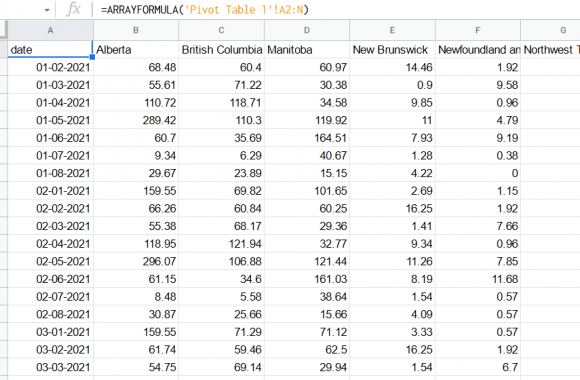
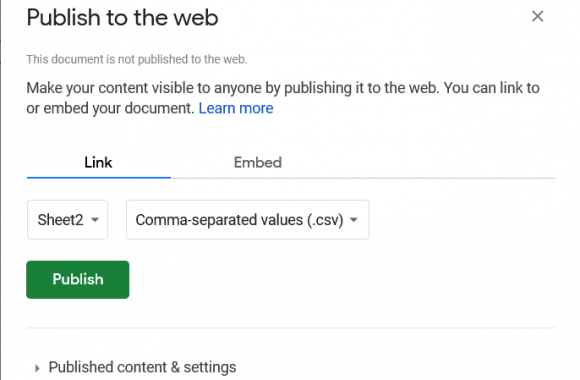
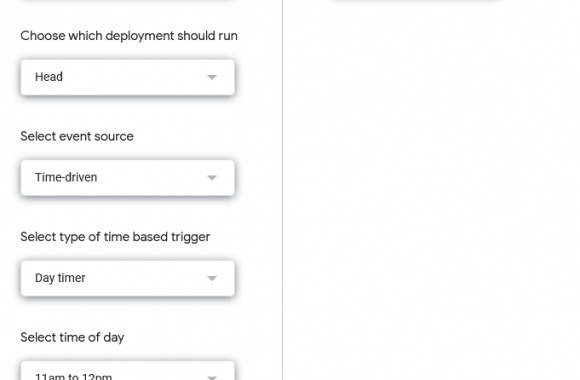
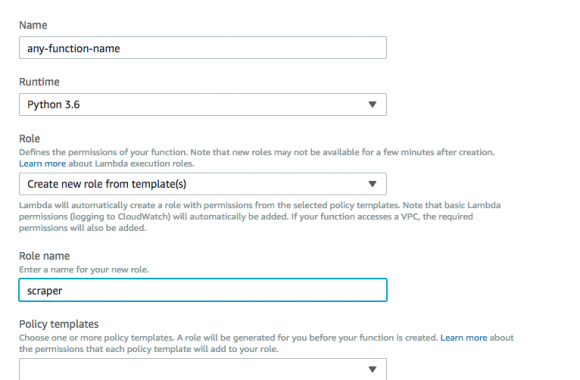
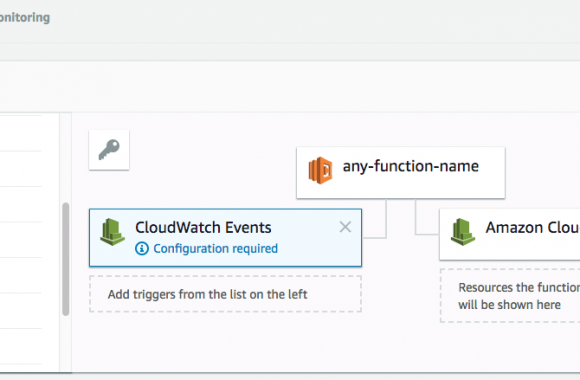
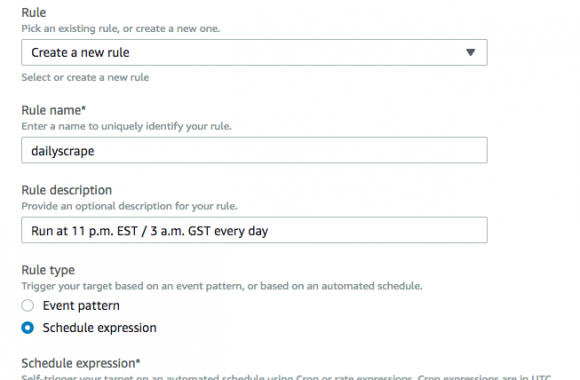
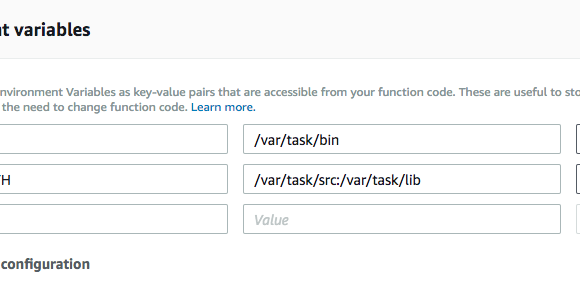
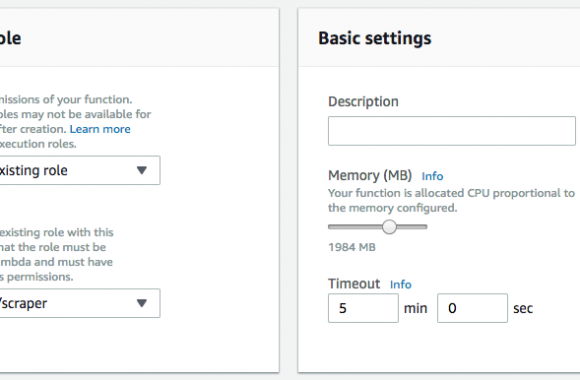
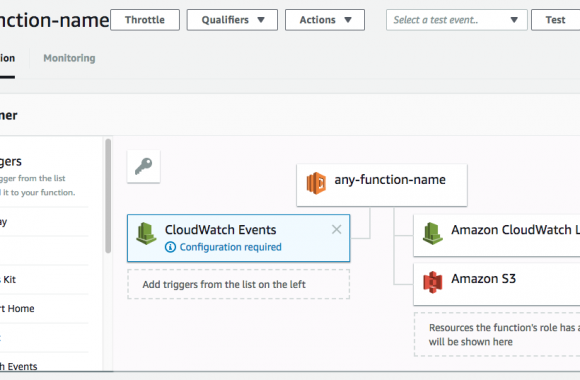
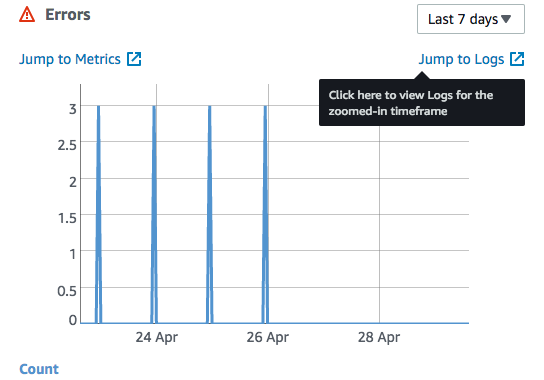
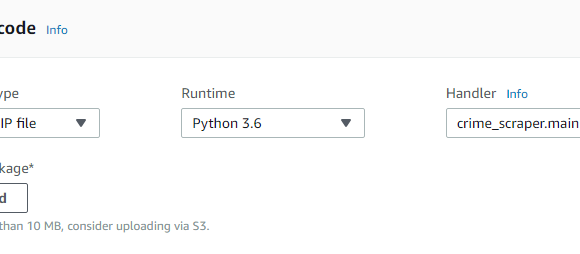
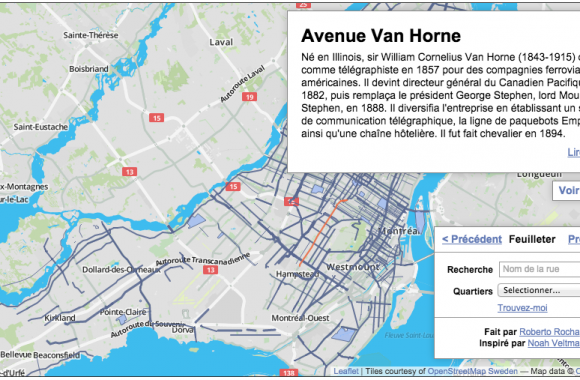
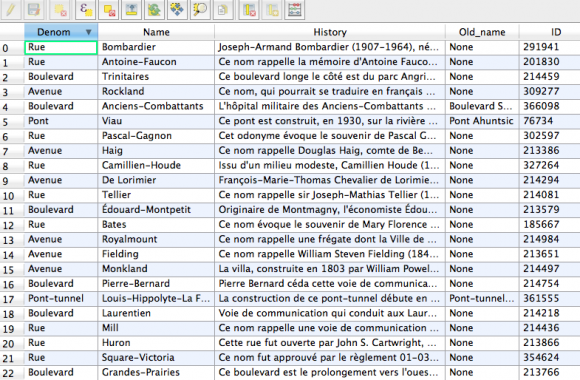
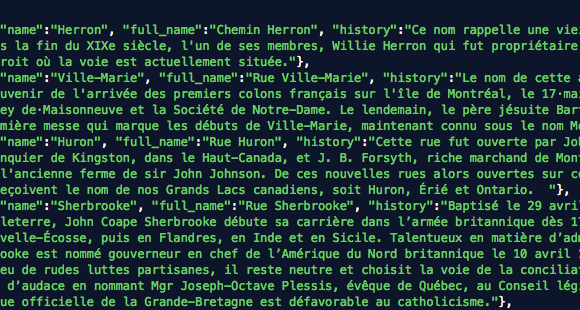
Wanna skip the blabla and get right to the code? Access the Colab notebook here. I recently took a short course on DeepLearning.ai called Pair Programming with LLMs, where you learn how to use Google’s PaLM2 language model to help write, debug, and explain code within a Jupyter Notebook environment. Well, PaLM is old news, […]