
Wanna skip the blabla and get right to the code? Access the Colab notebook here.
I recently took a short course on DeepLearning.ai called Pair Programming with LLMs, where you learn how to use Google’s PaLM2 language model to help write, debug, and explain code within a Jupyter Notebook environment.
Well, PaLM is old news, but the idea is solid. Using an LLM in a code notebook has a few advantages:
- You stay in the same environment, no need to switch between an AI chatbot and your notebook.
- Cost: you only pay for the API usage, no need to fork over a monthly fee for something like ChatGPT.
But there is one downside: it’s trickier to have a conversation with the model through the API to ask follow-up questions. You have to set up a system to keep track of previous exchanges with every new call. It’s possible, just a bit more work.
I decided to give it a shot anyway, and compare five leading models on a series of data-heavy tasks:
- Google’s Gemini
1.0 Pro1.5 - OpenAI’s GPT-4
- Anthropic’s Claude 3
- Meta’s Code LLaMa 34B
- Mistral 7B
UPDATE: Since I published this, Google gave me API access to the latest Gemini 1.5 model. I re-ran the prompts but the results were not noticeably better.
Wait, what’s pair programming?
When you learn how to drive, you’re on the driver’s seat while the instructor is the passenger and guides you through it. Pair programming is the same idea: the novice coder is on the keyboard, while the mentor offers guidance.
It’s a great way to learn, and it’s how I structure my mentoring sessions.
But you don’t always have the luxury of having a human guide around all the time. Although LLMs are prone to hallucinations, they are proving valuable as coding assistants. They don’t write perfect code, but write enough to save a lot of typing. You still have to understand the code to make it work.
The results
My goal was not to benchmark models on their code quality (lots of folks already do that), but to get a sense of which one would be most convenient for my needs as a data journalist/analyst, and require the least amount of hand-holding.
I tested the LLMs on five tasks:
- Scraping a simple website
- Scraping a complicated (impossible, really) website
- Generating a SQL query
- Reshaping a gnarly Excel file into tidy data for analysis
- Training a simple machine learning model for prediction
Full code, prompts and results are in this Colab notebook.
Simple scraping
I asked the LLMs to write Python code to scrape a simple online store and grab just four bits of data: the product title, price, designer name, and a URL of the thumbnail image, and save them to a CSV file. The goal was to see if the LLMs actually visited the site, inspected the page source and extracted the relevant classes and IDs. I also asked them to paginate across all pages.
Winner: No clear winner
Most models appeared to guess how the website is structured, and generated fairly boilerplate code with made-up element classes. You would need to manually find the target element attributes and plug them in, which isn’t too bad. GPT-4 was the most honest, and told me I should adjust the code as needed.
Hard scraping
I asked them to write a scraper for the Canadian adverse drug reaction database. This task is unfair, as it’s nearly impossible to scrape without a headless browser like Selenium. Also, the data is available for download, so scraping is pointless.
The point was to see if the LLM actually goes to the website, inspects how it works, realizes the challenge, and comes up with something that’s close enough, or how much it just spits out generic scraping patterns.
The ideal script would use the site’s internal API and construct a POST request with a reasonable JSON payload.
Winner: Claude, sort of.
Given the impossibility of the task, Claude’s code was the closest to something functional, and it showed evidence that it actually visited the site.
SQL queries
I asked it to solve the hardest problem in the LeetCode Top 50 SQL interview questions challenge. It involves writing subqueries, window functions and joins.
Winners: GPT-4, Claude and LLaMa
Turns out writing SQL is really easy for LLMs.
Wrangling data with pandas
I got a really gnarly Excel file with crime data from Statistics Canada that needed A LOT of restructuring before it could be used for analysis. It looked like this:
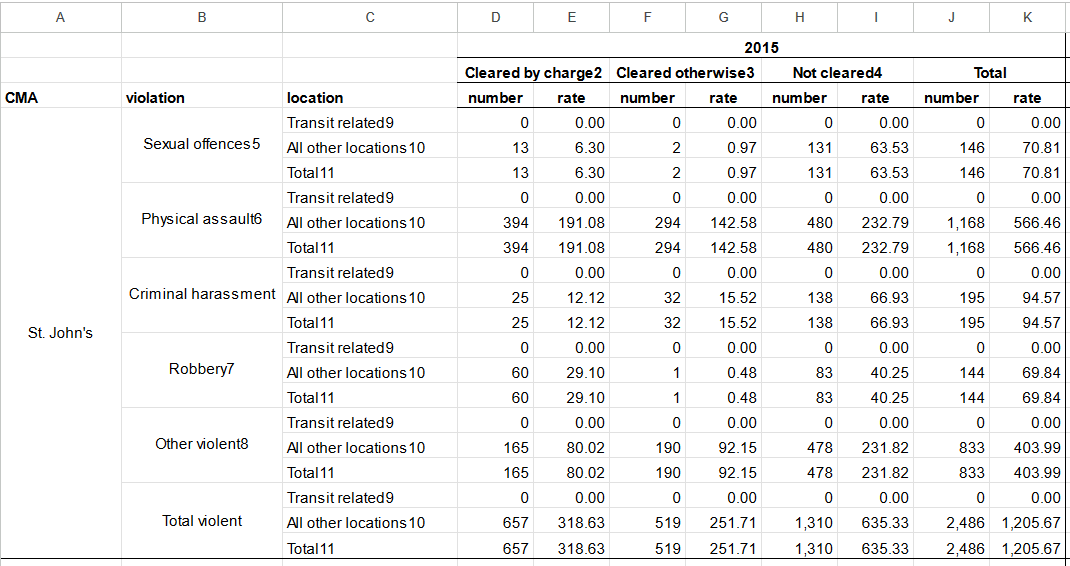
I needed it to look like this:
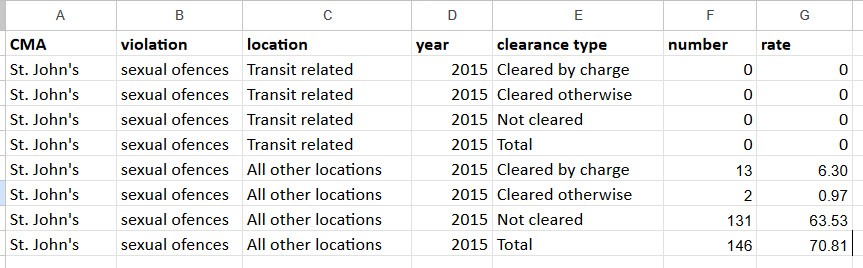
It’s a complex reshaping job that took me almost two days.
Winners: GPT-4 and Claude
Although neither wrote perfect code, they were the ones that needed the least manual tweaking.
Machine learning
I gave the MMLs a fictional schema of of app usage data and told them to be a data scientist. I asked them to generate code to train a logistic regression model to predict 30-day retention based on all other variables in the data.
I couldn’t test the code, since I made everything up, but to my surprise, they generated nearly identical code, differing only in the evaluation metrics for the model. They all used scikit-learn, knew to convert categorical columns to dummy binary values and used Recursive Feature Elimination (RFE) to identify the most important features.
Mistral was the only model that used a datetime column as a training variable; all others ignored it.
Who knew that language models created by ML would be so good at doing ML themselves?
Winner: All of them, except LLaMa, which instead of generating code, returned an internal dialogue about fine-tuning a ML model. Mistral gets extra points for ambition.
Conclusion
Although all models did somewhat well, GPT-4 and Claude 3 stood out by generating code that was easy to read and required the least amount of editing.
Code LLaMa was the least impressive. It should be noted that I used the codellama-34b-instruct model, which is the most advanced code-generating model available through the API. LLaMa also has a Python-specific model, but not through the API.
Gemini and Mistral were meh, neither great nor useless.