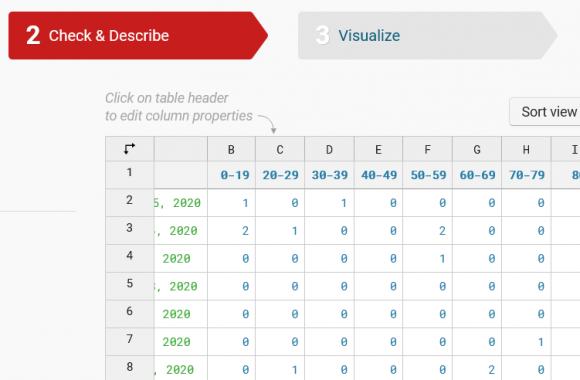
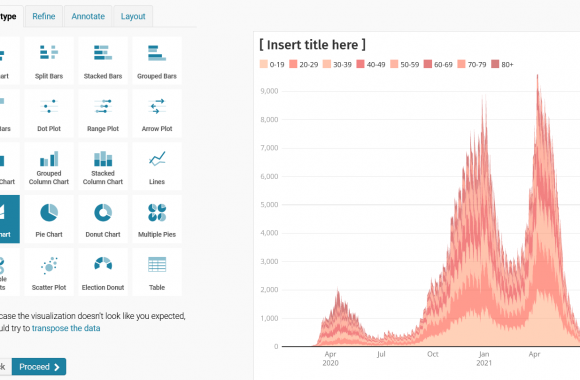
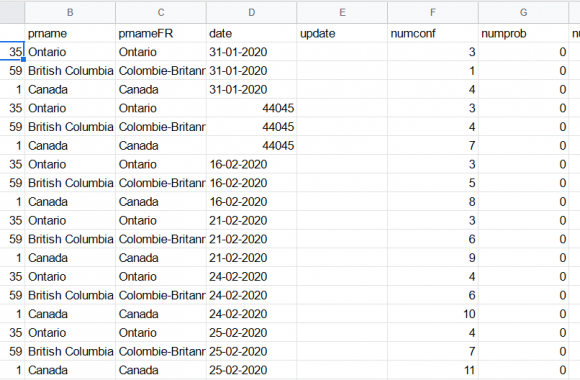
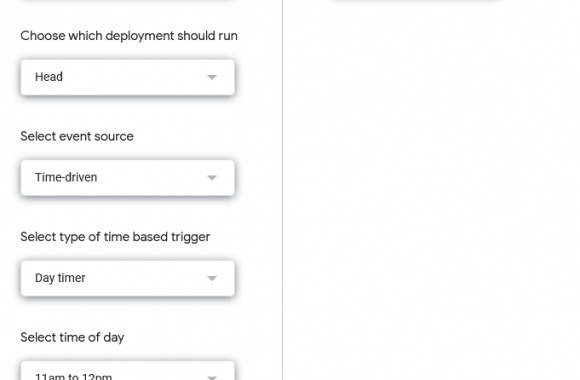
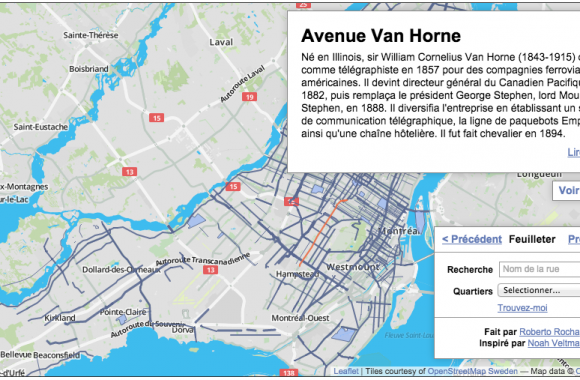
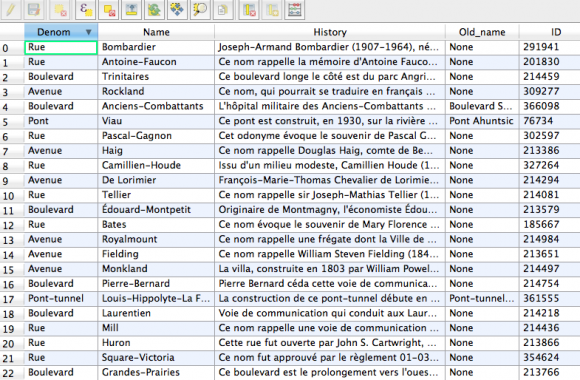
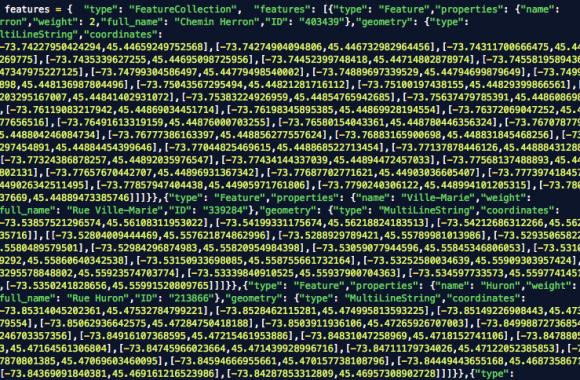
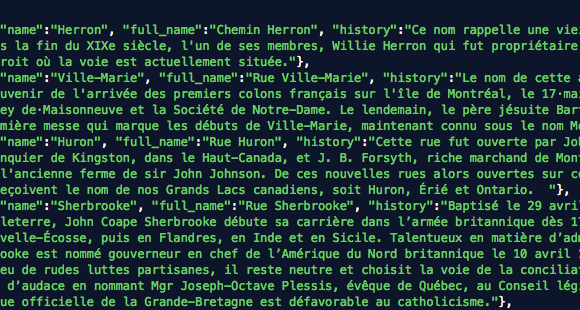
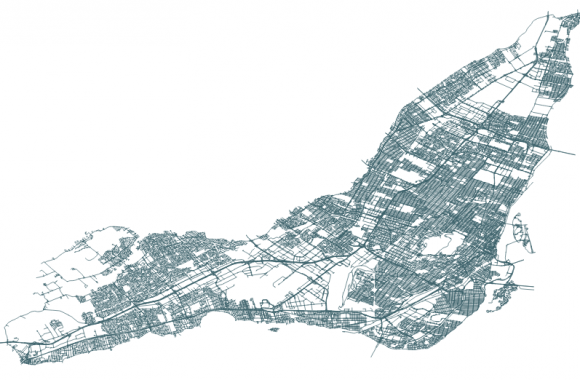
TL;DR: Use the en_core_web_trf transformer model with Spacy to get much more accurate named entity recognition with multilingual text. Entity recognition is one of the marvels or current technology, as least from a journalist’s perspective. There was a time journalists had to read through hundreds, maybe thousands of documents, highlight names of people, companies and […]